Article Text

Abstract
Introduction The infection fatality rate (IFR) of COVID-19 has been carefully measured and analysed in high-income countries, whereas there has been no systematic analysis of age-specific seroprevalence or IFR for developing countries.
Methods We systematically reviewed the literature to identify all COVID-19 serology studies in developing countries that were conducted using representative samples collected by February 2021. For each of the antibody assays used in these serology studies, we identified data on assay characteristics, including the extent of seroreversion over time. We analysed the serology data using a Bayesian model that incorporates conventional sampling uncertainty as well as uncertainties about assay sensitivity and specificity. We then calculated IFRs using individual case reports or aggregated public health updates, including age-specific estimates whenever feasible.
Results In most locations in developing countries, seroprevalence among older adults was similar to that of younger age cohorts, underscoring the limited capacity that these nations have to protect older age groups.
Age-specific IFRs were roughly 2 times higher than in high-income countries. The median value of the population IFR was about 0.5%, similar to that of high-income countries, because disparities in healthcare access were roughly offset by differences in population age structure.
Conclusion The burden of COVID-19 is far higher in developing countries than in high-income countries, reflecting a combination of elevated transmission to middle-aged and older adults as well as limited access to adequate healthcare. These results underscore the critical need to ensure medical equity to populations in developing countries through provision of vaccine doses and effective medications.
- COVID-19
- Epidemiology
- Public Health
- Systematic review
- Serology
Data availability statement
Data are available in a public, open access repository.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
What is already known on this topic
Prior meta-analyses of data from high-income countries have shown that the COVID-19 infection fatality rate (IFR) increases exponentially with age while seroprevalence (as measured by antibodies against SARS-CoV-2) has been markedly lower for older adults relative to younger adults.
What this study adds
We analyse serology and mortality data from 62 studies of 25 developing countries, and we find that age-stratified IFRs are about two times higher than the benchmark metaregression for high-income countries.
Indeed, population IFR in developing countries is similar to that of high-income countries, because differences in population age structure are roughly offset by disparities in healthcare access and elevated infection rates among older age cohorts.
How this study might affect research, practice or policy
Our findings underscore the urgency of disseminating vaccines and effective medications throughout the developing world.
Introduction
An important unknown during the COVID-19 pandemic has been the relative severity of the disease in developing countries compared with higher-income nations. The incidence of fatalities in many developing countries appeared to be low in the early stages of the pandemic, suggesting that the relatively younger age structure of these countries might have protected them against the harms of the disease. More recently, however, it has become clear that the perceived differences in mortality may have been illusory, reflecting poor vital statistics systems leading to under-reporting of COVID-19 deaths.1 2 Moreover, relatively low mortality outcomes in developing countries would be starkly different from the typical pattern observed for many other communicable diseases, reflecting the generally lower access to good-quality healthcare in these locations.3 4
As shown in table 1, mortality attributable to COVID-19 in many developing locations exceeds 2000 deaths per million. Of the 12 nations with the highest number of deaths attributed to COVID-19, eight are developing countries. Furthermore, these statistics may understate the true death toll in a number of lower-income and middle-income countries. Numerous studies of excess mortality have underscored the limitations of vital registration and death reporting, particularly in developing countries.1 2 5–9 For example, recent studies of India have found that actual deaths from COVID-19 were about 10 times higher than those in official reports.2 5 Similarly, a study in Zambia found that only 1 in 10 of those who died with COVID-19 symptoms and whose postmortem COVID-19 test was positive were recorded as COVID-19 deaths in the national registry.10 Strikingly, the continuation of that study has demonstrated the catastrophic impact of COVID-19 in Zambia, raising the overall mortality by as much as 5–10 times relative to a normal year.11
Confirmed COVID-19 deaths as of 20 March 2022
There has, however, been a relative dearth of systematic research concerning the early experience of COVID-19 and the associated infection fatality rate (IFR) in developing countries. Previous evaluations have largely focused on assessing these patterns in high-income countries, where high-quality data on seroprevalence and fatalities has been readily available throughout the pandemic.12 13 In particular, seroprevalence studies conducted in high-income countries in 2020 found low overall prevalence of antibodies to COVID-19 (generally less than 10%),14 with much lower prevalence among older adults compared with younger cohorts. Analysis of these data has clearly underscored the extent to which the IFR of COVID-19 increases exponentially with age; that is, the disease is far more dangerous for middle-aged and older adults compared with children and young people.12 13 15 Two prior meta-analytical studies have considered variations in IFR by age but did not consider the possibility that IFR in developing locations might differ systematically from high-income countries due to healthcare quality, access and other socioeconomic factors.12 16
Objectives
Determine overall prevalence of COVID-19 infection in locations in developing countries.
Assess age-specific patterns of seroprevalence in these locations.
Estimate age-specific IFRs and compare to benchmark values for high-income countries.
Investigate possible reasons for differences in population IFR between locations.
Methods
To perform this meta-analysis, we collected published papers, preprints and government reports of COVID-19 serology studies for which all specimens were collected before 1 March 2021 and that were publicly disseminated by 17 December 2021. The full search methodology is given in online supplemental appendix 1A. The study was registered on the Open Science Foundation: https://osf.io/edpwv/
Supplemental material
We restricted the scope of our analysis to locations in developing countries using the classification system of the International Monetary Fund (IMF); that is, we excluded locations that the IMF classifies as ‘high-income countries’.17 In some contexts developing countries are also described as low-income to middle-income countries or as emerging and developing economies.
Inclusion/exclusion criteria
Our analysis only included studies that had a random selection of participants from a sample frame representative of the general population.18 19 Consequently, studies of convenience samples—such as blood donors or residual sera from commercial laboratories—were excluded. Such samples are subject to intrinsic selection biases that may vary across different settings and hence would detract from systematic analysis of the data. Indeed, there is abundant evidence from the pandemic that convenience samples provide inaccurate estimates of seroprevalence, with assessments indicating that they are likely to overestimate the true proportion infected.20 21
A crucial part of our analysis entailed adjusting raw seroprevalence to reflect the sensitivity and specificity of the particular assay used in each serology study, and to construct credible intervals that reflect uncertainty about assay characteristics as well as conventional sampling uncertainty. Where a reported study did not include that information, we requested it from study authors. Other data needed and extracted for the analysis included start and end dates of specimen collection, the specific assay used and age-specific serology data.
See online supplemental appendix 1b for further details on inclusion and exclusion criteria.
Deaths
For locations with publicly available databases of all individual cases, we tabulated the fatality data to match the age brackets of that serology study, using cumulative fatalities as of 14 days after the midpoint date of specimen collection to reflect the time lags between infection, seropositivity and fatal outcomes. In the absence of individual case data, we searched for contemporaneous public health reports and tabulated cumulative deaths as of 28 days after the midpoint date of specimen collection to incorporate the additional time lags associated with real-time reporting of COVID-19 fatalities (see online supplemental appendix 1d for discussion of death lags).
Matching prevalence estimates with subsequent fatalities is not feasible if a serology study was conducted in the midst of an accelerating outbreak. Therefore, as in previous work,15 we estimated seroprevalence but did not analyse IFRs for locations where the cumulative death toll increased by three times or more over the 4-week period following the midpoint date of specimen collection. For details, see the online supplemental appendix 1d. In instances where we were not able to match deaths to serology data, or there were accelerating outbreaks, we used this information to look at serology only.
Additionally, we extracted data on excess deaths for all countries that were included in our IFR analysis. We used two primary sources of estimates on excess mortality: the Institute for Health Metrics and Evaluation (IHME)22 and the World Mortality Dataset (WMD).1 The IHME produces national or regional estimates of excess mortality for every location included in this review, while the WMD has estimates for a subset of those locations. We then computed the ratio of excess mortality to reported fatalities for each location in order to assess the impact of potential death under-reporting, and calculated adjusted IFRs using excess mortality as the numerator, as well as the ratio between IFRs calculated using reported and excess deaths. We used excess mortality as it is likely to better represent the true burden of COVID-19 accurately in developing nations.1
Adjustment for seroreversion
For those assays used in serology studies included in our analysis, we classified each assay’s risk of seroreversion (high, medium or low) based on longitudinal serology studies and serological analysis of prior RT-PCR positive cases. For each location for which the assay used in serology was classified as having high risk of seroreversion, we made adjustments to the data on assay sensitivity. See online supplemental appendix 2a for further details.
Statistical analysis
We use a Bayesian modelling framework to simultaneously estimate age-specific prevalence and IFRs for each location in our study. First, we model age-specific prevalence for each location at the resolution of the serology data reported. Then, we model the number of people that test positive in a given study location and age group as coming from a binomial distribution with a test positivity probability that is a function of the true prevalence, sensitivity and specificity, accounting for seroconversion and seroreversion (see the online supplemental appendix 2B).
As in Carpenter and Gelman (2020),23 we consider sensitivity and specificity to be unknown and directly model the lab validation data (eg, true positives, true negatives, false positives, false negatives) for each test. Independent weakly informative priors are placed on the seroprevalence parameters, and independent, informative priors akin to those in Carpenter and Gelman23 are placed on the sensitivity and specificity parameters. To avoid assumptions about the variability of prevalence across age within a serology age bin, we aggregate deaths for each location to match their respective serology age bins. Independent mildly informative priors are assumed on the age-group-specific IFR parameters.
Prevalence for a given age group and location is estimated by the posterior mean and equal-tailed 95% credible interval. Uniform prevalence across age is deemed plausible for locations where the 95% credible intervals for the ratio of seroprevalence for age 60 years and older over the seroprevalence estimate for ages 20 years to 60 years contains 1.
IFR calculation and comparison
We model the number of individuals at a given location and age group that are reported as dying of COVID-19 as Poisson distributed with rate equal to the product of the age group IFR, age group population and age group prevalence. For locations where deaths were reported separately for different age bins this model provides IFR estimates for specific age groups and for broader population cohorts, including adults aged 18–65 years. For locations where death data were not disaggregated by age the model provides a population IFR. The model was implemented in the programming language R, with posterior sampling computation implemented with the Stan software package.24
To perform a meta-analysis of age-specific IFRs across locations, we conduct a metaregression with random effects. In the metaregression, the dependent variable is the estimated IFR for a specific age group in a specific geographical location, the explanatory variable is the median age of that particular age group, and the SD of each idiosyncratic error is taken from the Bayesian analysis described above. We used a random-effects procedure to allow for residual heterogeneity between studies and across age groups by assuming that these divergences are drawn from a Gaussian distribution. We also allowed for fixed effects by location, to account for locations that deviate from the norm. Since the metaregression used IFR estimates based on reported deaths, we compared the location-specific fixed effects to two estimates of the ratio of excess mortality to COVID-19 deaths in each location. We also compared these metaregression results to a prior metaregression of age-specific IFR for high-income countries;15 further details are given in online supplemental appendix 2d and table A5. This was performed using the meta regression procedure in Stata V.17. Finally, we computed population IFRs adjusted for COVID-19 death undercounting and compared these estimates to the proportion of well-certified deaths.
Covariates
We selected covariates that were judged likely to have an impact either on the IFR of COVID-19 itself or on the accuracy of official data on COVID-related mortality based on prior research and expertise. Such covariates included GDP per capita and measures of healthcare capacity; the complete list is provided in online supplemental appendix 1f. Where possible, we extracted these covariates at a state or regional level within a country; otherwise, they were identified at a national level. In instances where a covariate was only available at the national level, we aggregated location-specific seroprevalence and IFRs by weighting each location using the square root of the number of serology specimens collected in that location.
Results
We identified a total of 2384 study records, with 2281 records identified from online databases and a further 124 from Twitter, Google Scholar and a prior publication.25 After excluding 2062 records, we assessed 343 records and determined that 97 studies satisfied the criteria for inclusion in the final analyses, of which 62 studies (representing a total of 25 developing countries) could be used to produce IFR estimates; see online supplemental appendix 1c for details. The geographical distribution of these studies is shown in figure 1, while table 2 provides a list of the studies used in producing IFR estimates, including the specimen collection dates and the assay used in each study. Further details are provided in our GitHub repository https://covid-ifr.github.io/.
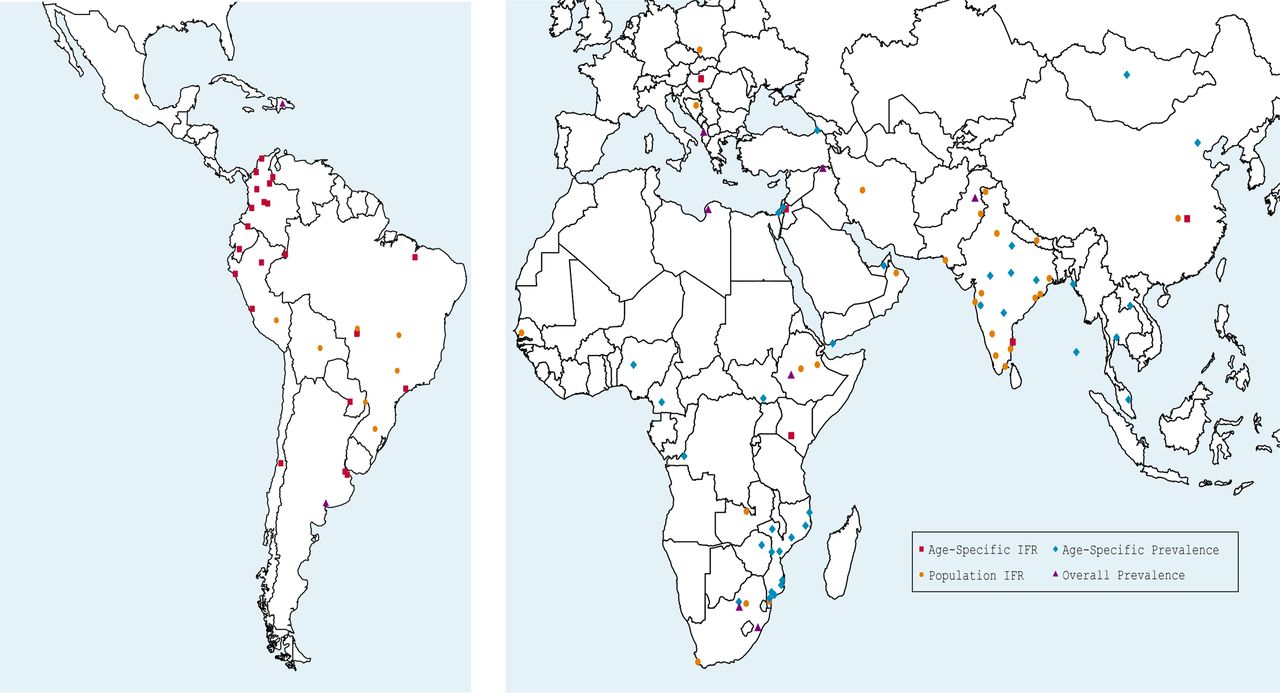
Map of study locations. IFR, infection fatality rate.
Included studies for infection fatality rate (IFR)
Seroprevalence
As shown in figure 2A and 2B, seroprevalence reached relatively high levels in numerous locations in developing countries during the time frame covered by our analysis. The upper panel shows estimates from studies where specimens were collected between April and September 2020, while the lower panel shows corresponding estimates for the period from October 2020 to February 2021.

Estimates of seroprevalence.
In most developing country locations, seroprevalence was roughly uniform across age strata. Figure 3 shows the heatmap of age-specific seroprevalence across all age cohorts. As shown in figure 4, the ratio of seroprevalence for older adults (ages 60+ years) compared with middle-aged adults (ages 40–59 years) is indistinguishable from unity in most of these locations. While many locations had a ratio below 1, the majority of the areas were very substantially above the ratio for higher-income areas (green shaded region), and the point estimates were not markedly below 1, indicating minimal difference in infection rates between older and younger adults in developing nations.

Age‐specific seroprevalence by location.

Ratio of seroprevalence for older adults (60+ years) compared with adults (40–59 years).
Infection fatality rates
Our statistical analysis produced age-specific IFRs and CIs for 28 locations, and population IFRs for those locations as well as an additional 27 places. The full results of this analysis are shown in the online supplemental appendix 3. We obtain the following metaregression results:

where IFR is expressed in percentage points, and the SE for each estimated coefficient is given in parentheses. These estimates are highly significant with t-statistics of −28.7 and 21.0, respectively, and p values below 0·0001. The residual heterogeneity is τ2=0.039 (p<0.0001) and I2=92.5, confirming that the random effects are essential for capturing unexplained variations across studies and age groups. The adjusted R2 is 91.1%. Location-specific fixed effects are only distinguishable from zero for three locations: Maranhão, Brazil (−0.50); Chennai, India (−0.68); and Karnataka, India (−1.29).
The metaregression results can be seen in figure 5. Nearly all of the observations fall within the 95% prediction interval. The importance of the location-specific effects is readily apparent. Indeed, these effects imply that the age-specific IFRs for Maranhão are about 1/3 of the metaregression prediction, while those for Chennai and Karnataka are 1/5 and 1/20, respectively.

metaregression results. IFR, infection fatality rate.
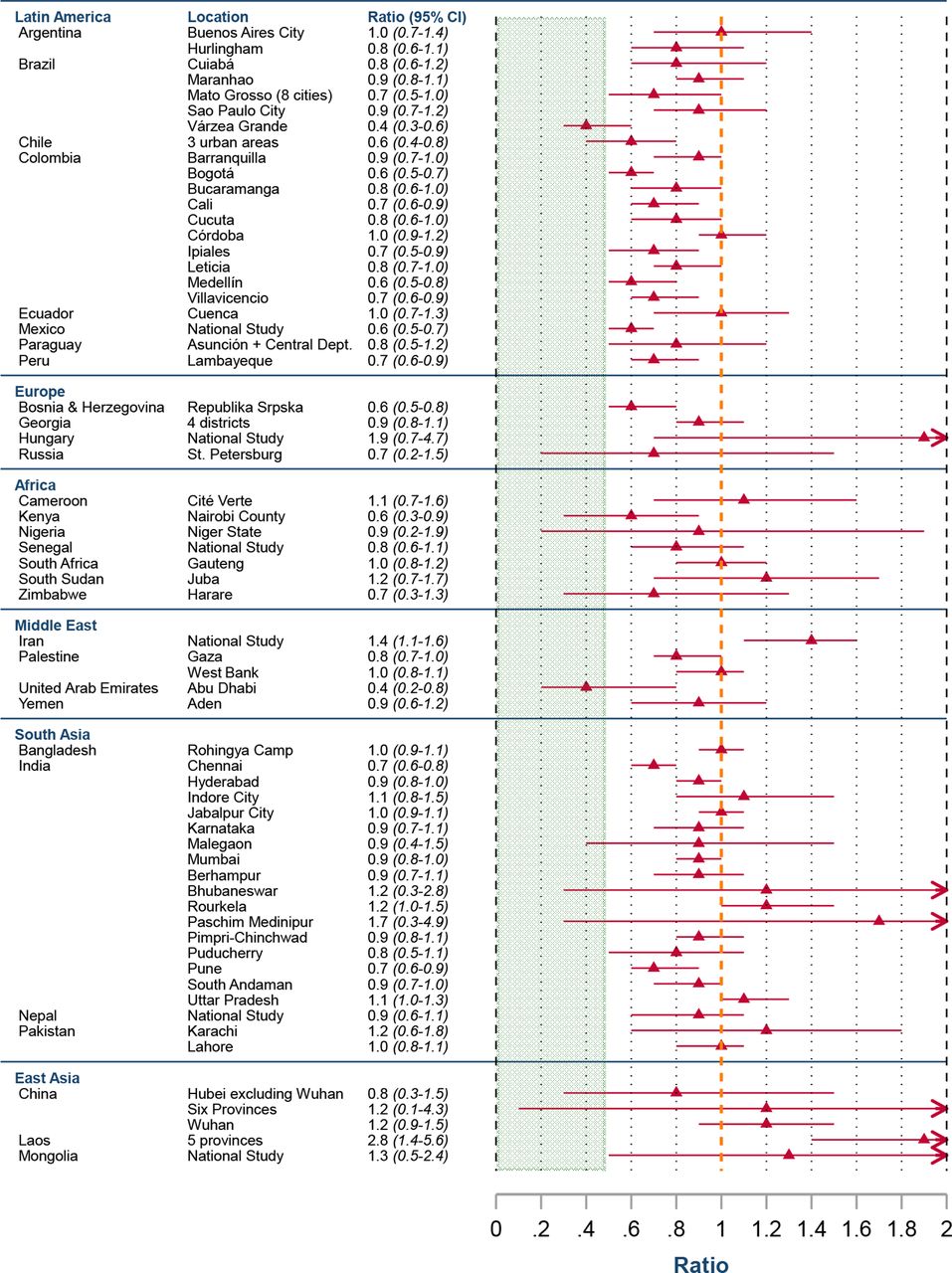
This metaregression analysis uses age-specific IFRs based on reported COVID-19 deaths in each location. As a crosscheck, table 3 reports the ratio of excess mortality to reported deaths for each of these locations. For nearly all of these locations, the ratio is indistinguishable from unity; that is, reported COVID-19 deaths are broadly consistent with the evidence from excess mortality assessments. There were three exceptions (Chennai, Karnataka and Nairobi, Kenya), two of which had significant location-specific effects in the metaregression.
Ratio of excess mortality to reported COVID-19 deaths
The precision of IFR estimates varied by age. At lower age groups, the number of deaths becomes very small, and thus the uncertainty is large regarding the IFR. Conversely, at older ages the number of infections and deaths can be very small in countries with extremely small populations of those aged over 65 years, and thus these estimates are also uncertain. The detailed analysis of age-specific IFR for each location is provided in online supplemental appendix figure A6.
Figure 6 shows that these age-specific IFRs are systematically higher than those of a prior metaregression estimated using studies of high-income countries.15 That benchmark metaregression has a slope of 0.0524 (95% CI 0.0499 to 0.0549), and a Welch test strongly rejects the hypothesis of equality in the slope parameters for developing countries versus high-income countries with a value of p<0.0001. This figure also shows a variant of our metaregression, estimated using studies of developing country locations conducted over the same time frame as in the benchmark metaregression (April to September 2020) and excluding the three outlier locations (Maranhão, Chennai and Karnataka); the estimated intercept and slope coefficient of this variant (−2.68 and 0.0480, respectively) are statistically indistinguishable from the baseline values shown above.

IFR in developing countries compared to high‐income countries. IFR, infection fatality rate.
Figure 7 shows estimates of population IFR at ages 18–65 years, adjusted for excess mortality using the ratios shown in table 3. To facilitate comparability across locations, these estimates use a standardised age structure to aggregate the age-specific prevalence and fatalities in each location. Corresponding estimates, using the actual population age structure of each location, are shown in online supplemental appendix figure A12.
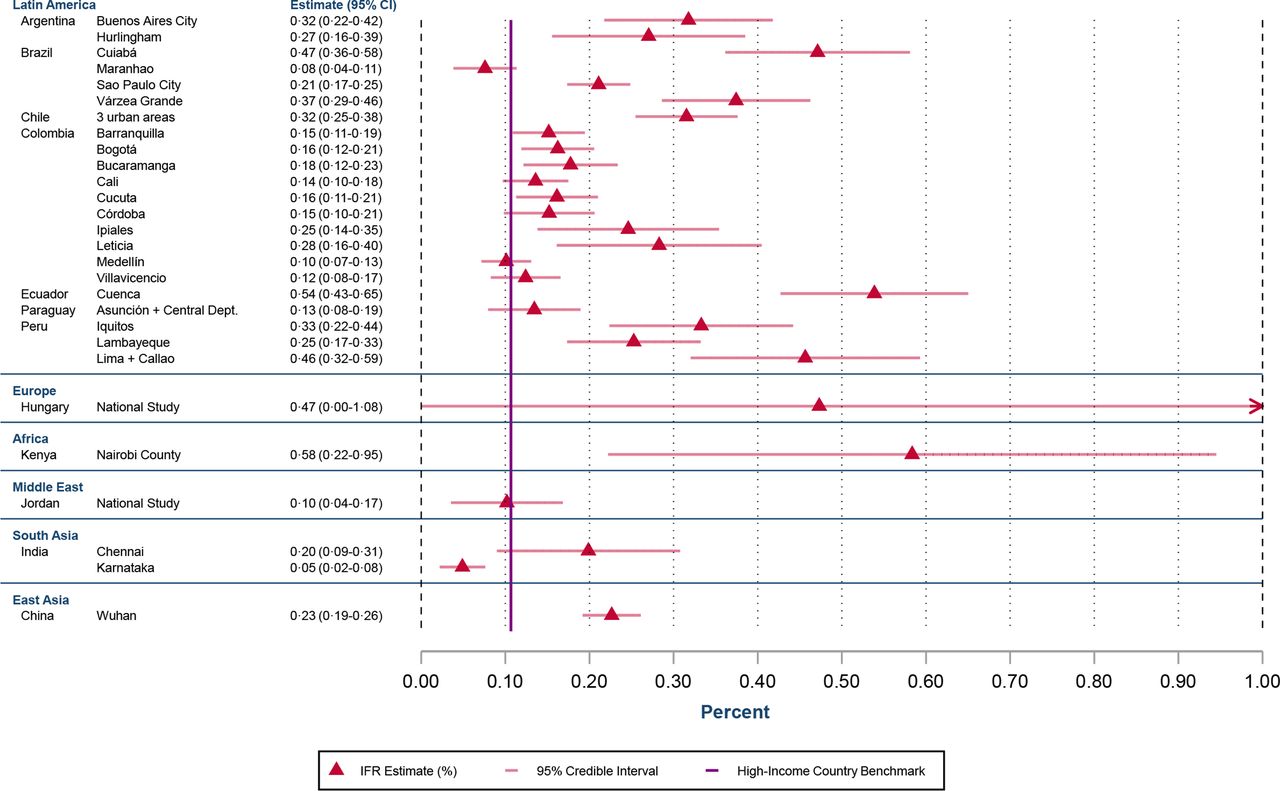
Population IFR for ages 18–65 years. IFR, infection fatality rate.
Assessment of death reporting
For the full set of locations for which population IFR can be assessed, we found that the adequacy of death certification was highly significant in explaining cross-country variations. As shown in figure 8, the median value of population IFR was about 0.5% in countries where a majority of deaths were well certified (using Sustainable Development Goal (SDG) assessments26 conducted prior to the pandemic), compared with only 0.05% in countries with lower proportions of well-certified deaths. In the latter set of countries, adjustments for excess mortality shift the population IFR upwards by an order of magnitude, to a median of 0.6%. Indeed, the population IFR for Zambia increases from 0.23% to 1.96%—the highest value for any country in our sample. In contrast, the excess mortality adjustments make relatively little difference for countries with a majority of well-certified deaths.

Population IFR and well‐certified death registrations. IFR, infection fatality rate.
Finally, we considered the extent to which the adjusted measures of population IFR were robust to alternative estimates of the ratio of excess mortality to reported deaths. As shown in figure 9 the estimates from IHME and WMD were generally well aligned, with just a small number of exceptions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Excess mortality adjusted population IFRs. IFR, infection fatality rate.
The adjusted population IFRs had a median value of 0.49% using the IHME estimates and 0.58% using the WMD estimates.
Discussion
COVID-19 has had a severe burden on developing countries. Prevalence in developing countries is roughly uniform across age groups, in contrast to the typical pattern in high-income countries where seroprevalence is markedly lower among middle-aged and older adults who are most vulnerable to this disease. Moreover, the IFR is substantially higher in developing countries compared with high-income countries.
At 20 years of age, the mean IFR in developing countries is 2.7 times higher than that in high-income countries and at age 60 years the risk is doubled. At the oldest ages, this discrepancy is reduced, with only a modestly increased risk at age 80 years. These relationships have also been found with socioeconomic status within specific places such as Santiago, Chile.7 This warrants further research to understand why access to healthcare and other socioeconomic issues appear to have a larger impact on survival at younger ages. This finding does not rely on any specific modelling assumptions such as log-linearity, which is shown by the readily apparent disparity in figure 7, showing the age-standardised IFR for each individual location compared with the benchmark of high-income countries.
The elevated IFR in developing nations only becomes apparent when stratifying by age and adjusting for death under-reporting. Indeed, the quality of the vital statistics system tends to be linked to the overall level of economic development, and hence some previous studies of unadjusted data have incorrectly inferred that population IFRs are lower in developing countries than in high-income countries.27–30
Our results are important for addressing questions that have arisen about whether COVID-19 was less dangerous for populations in sub-Saharan Africa compared with locations elsewhere.31–33 As shown in figure 7, the age-standardised population IFR of Nairobi County, Kenya is about five times higher than the high-income country benchmark. Likewise, figure 8 shows that the population IFR (adjusted for under-reporting of COVID-19 fatalities) exceeds 0.5% for locations in Ethiopia, Mozambique and South Africa; the sole exception is Senegal, perhaps due to even more severe death undercounting than captured by the estimated ratio. These results underscore the importance of drawing inferences from representative samples rather than from convenience samples.34–36
These results are consistent with the pattern observed for most other communicable diseases.3 4 In locations with little ability to work from home, where quarantine is difficult or impossible, where opportunities for physical distancing and access to sanitation are poor, with lower healthcare resources, and where even basic resources such as supplemental oxygen are in short supply, people have fared substantially worse during the pandemic than in high-income settings. Indeed, in low-income settings where fewer hospital beds and healthcare workers are available, COVID-19 has caused great devastation and an enormous death toll. With a much higher IFR, particularly in younger people, the ultimate burden for developing nations from COVID-19 is likely to be very high.
Another important facet of our results is that seroprevalence was both higher and consistent across age groups in developing countries—a striking contrast to the typical pattern in high-income countries, where prevalence among older adults was markedly lower than among younger adults.15 37 38 Evidently, it is very difficult to insulate elderly people from the virus in a slum or a rural village. This is likely also impacted by the higher proportion of multigenerational families in developing countries,39 a known risk-factor for COVID-19 infection and death.40 41 For example, seroprevalence in slum neighbourhoods of Mumbai was about four times higher than in non-slum neighbourhoods.42 Our analysis indicates that the relatively uniform prevalence of COVID-19 in developing countries has dramatically increased the number of fatalities in these locations.
Our findings reinforce the conclusions of previous studies that have assessed the IFR of COVID-19.13 43 In particular, COVID-19 is dangerous for middle-aged adults, not just the elderly and infirm.15 Our metaregression results are well aligned with IFR estimates produced for specific locations in developing countries (see supplementary online supplemental appendix table A8).
Our analysis underscores that incomplete death reporting is a crucial source of apparent differences in COVID-19 death rates. In particular, this is related to the proportion of deaths that are assigned to so-called ‘garbage codes’.26 44 45 These deaths are, by definition, not included in national tallies of the population that has died from COVID-19. As shown in figure 8, the IFR is on average 10 times higher in locations with reasonably adequate vital statistics compared with other locations where a majority of deaths are not well certified.
The divergence between population IFRs for locations is similar whether adjusted for death certification or excess mortality. Adjustment for estimates of excess mortality produced location population IFRs that were consistent with IFRs produced in the age-stratified analysis, aside from a few minor outliers. As shown in figure 8, the median of these population IFRs for developing nations, once adjusted for undercounting of COVID-19 deaths, was 0.58%, very similar to the median estimates of IFR for high-income countries.46
Excess mortality is a useful metric for adjusting IFR estimates in areas where deaths are well registered but not well certified; that is: captured in national vital statistics but without a specific cause of death.1 Nonetheless, caution is warranted in applying national estimates of excess mortality to specific regions within a country, recognising that death reporting systems may vary markedly with the degree of urbanisation and other socioeconomic factors. In the case of Ecuador, for example, the national estimate for the ratio of excess mortality to reported COVID-19 deaths in 2020 was 2.6 (1, 22), whereas that ratio was only 1.01 in the province of Azuay.47
Moreover, estimates of excess mortality may partly reflect indirect effects of the pandemic on other sources of mortality. On the one hand, non-pharmaceutical interventions (such as business closures) may reduce mortality from causes such as vehicle accidents.1 48 Conversely, mortality may be elevated by impaired access to healthcare for non-infectious diseases such as chronic cardiovascular disease or cancer,49 or by higher burdens of non-COVID infectious diseases such as malaria, tuberculosis or parasitic infections.50
Finally, the true burden of COVID-19 may be practically impossible to assess in locations where many deaths are never entered into the national vital statistics system.51 For example, total mortality in Kenya was lower in 2020 than in 2019, but those statistics should certainly not be interpreted as suggesting that Kenya was unscathed by the pandemic.22 Indeed, assessments of Kenya’s vital statistics found that only two-thirds of actual deaths were recorded in the system.51 Such considerations may explain other outliers in our analysis, such as Senegal, which remains far below similar locations even when estimates are adjusted for excess mortality.
A useful example in this case is Ethiopia. Despite national statistics not showing a large increase in deaths in Ethiopia during the pandemic, an epidemiological investigation of burial sites has revealed a huge increase in mortality during this period that is not part of the official reporting of COVID-19.52
In the absence of better death reporting, it is challenging to assess the extent to which differences in IFR across locations reflect systematic disparities in healthcare access, socioeconomic status and other indicators. Nonetheless, such effects have been clearly demonstrated by studies that have assessed distinct socioeconomic groups within specific regions such as Santiago, Chile.7 Moreover, these considerations are almost certainly relevant in interpreting our finding that age-stratified IFR is markedly higher in developing countries compared with high-income countries.53 Indeed, our results underscore the tragedy that a Zambian young adult with COVID-19 would be far more likely to die than a Swiss person of similar age.
Accounting for seroreversion and other assay characteristics is crucial for assessing seroprevalence accurately. Our analysis makes a novel contribution in providing a systematic assessment of the implications of seroreversion; that is, the proportion of people who develop antibodies but whose tests will fall below the limit of detection at a later date. Prior studies have either ignored this issue or have assumed that seroreversion occurs at a fixed geometric rate regardless of the assay used.12 13 In contrast, we have collated detailed information about the characteristics of all assays used in the serology studies included in our analysis, including data on seroreversion as well as test specificity and sensitivity; that information is fully described in online supplemental appendix 2a and b. Our analysis clearly indicates that the extent of seroreversion differs in magnitude depending on the assay used. Moreover, accounting for seroreversion had substantial implications for a number of locations in our analysis.
Our analysis makes a strong case for swifter action on vaccine and other medication equity. While countries have largely sought to protect their own populations, there is increasing commitment to ensuring that key populations in low-income and middle-income countries receive protection, at a minimum for their front-line health and other personnel. It is widely accepted that failing to control the pandemic across the globe will contribute to the emergence of additional strains of COVID-19, potentially undermining the efficacy of available vaccines.54 Current medication distribution efforts are grossly inequitable.55 Recent estimates suggest that fewer than 10% of people in low-income countries have received an immunisation, while the majority of people in high-income countries have had at least one vaccination.56 Similarly, the availability of effective medications such as Paxlovid is grossly inequitable across the globe.57
As with all research, our study is subject to a number of limitations. First, while we made every effort to capture seroprevalence data, including corresponding with dozens of researchers and public health officials worldwide, it is possible that some studies have been missed. However, it is unlikely that any small number of additional studies would make a material difference to our results.
Our analysis did not incorporate time series data on the evolution of COVID-19 deaths. However, some studies of high-income countries have shown how such data can be useful in refining assessment of IFR to incorporate the stochastic timing of COVID-19 deaths.13 58 Such analysis should be a priority for future research about IFR in developing countries.
While our analysis excluded convenience samples and focused exclusively on representative samples of the population, we recognise that such studies may also be susceptible to selection bias. Research conducted at various stages of the pandemic has found that individual preferences for testing can be associated with substantial bias in estimates of seroprevalence, with corresponding implications for estimates of population IFR.20 59 Such uncertainty can be incorporated into statistical models of prevalence and IFR.60 61 However, we did not follow such an approach here, because our statistical model already incorporates a number of other substantial sources of uncertainty.
Our work also did not consider non-mortality harms from COVID-19. Recent work has shown that even at younger ages a substantial fraction of infected individuals will have severe, long-lasting adverse effects from COVID-19.62 Consequently, the impact on the healthcare system and society may be far greater than would be reflected in mortality rates alone. Focusing only on survival rates obscures the large number of deaths that occur when many people are infected,63 the relatively high fatality rate of COVID-19 in comparison to other diseases and other causes of death,64 and non-mortality harms of COVID-19, such as hospitalisation from serious disease.62 Future work should address these non-mortality harms, including long COVID-19.
Another potentially serious limitation of our analysis is cross-reactivity in serological tests due to malaria. An investigation in Nigeria found that the commonly used Abbott and Euroimmun serological assays had a false-positive rate of 6.1% against prepandemic samples due to cross-reactivity with malarial antibodies.65 This would substantially lower specificity of the assay in areas with a high prevalence of past malaria infection, which would have the practical result of producing an upward bias of seroprevalence estimates and downward bias of IFR estimates. Thus, it is plausible that in areas with a large burden of malaria, that the IFR we have calculated represents a substantial underestimate.
Finally, our analysis only includes serology studies where specimen collection was completed by the end of February 2021. Consequently, our results do not reflect any potential changes in IFR that may have resulted from more recent advances in COVID-19 care, most notably, the development of novel antiviral medications and dissemination of vaccines. Of course, the IFR could also shift with the spread of new variants of SARS-CoV-2.66 However, given that the first major variant of COVID-19 was only identified in late 2020, and most vaccination campaigns in developing nations only began in early 2021, our time frame limits the impact that these factors should have on the results.
Conclusion
The prevalence and IFR by age of COVID-19 is far higher in developing countries than in high-income countries, reflecting a combination of elevated transmission to middle-aged and older adults, as well as limited access to adequate healthcare. These results underscore the critical need to accelerate the provision of vaccine boosters and newer effective medications to vulnerable populations in developing countries. Moreover, many developing countries require ongoing support to upgrade the quality of their vital statistics systems to facilitate public health decisions and actions, not only for the COVID-19 pandemic but for future global health concerns.
Code and data
All data and code are available publicly online.67
Data availability statement
Data are available in a public, open access repository.
Ethics statements
Patient consent for publication
Ethics approval
This study exclusively used publicly available aggregate data sets and published research, and hence no ethics approval was required.
Acknowledgments
The authors thank Ariel Karlinsky for assistance with death registration and mortality data.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
Handling editor Seye Abimbola
Twitter @HEARDatUNSW, @anup_malani, @satejsoman, @AnaCarolPecanha, @Enyew54639156
Contributors ATL and GM-K initiated and provided leadership for the project, and act as guarantors for the project. BKF and SP designated the Bayesian statistical framework. NO-B took primary responsibility for the search procedures, and performed the review of assay characteristics and seroreversion. ATL and NO-B reviewed each of the studies identified in the initial screening, and assessed and applied the exclusion criteria. SS took the lead in designing the data management procedures and setting up the GitHub repository. LB has developed an interactive tool that will be linked to the GitHub repository. SG, AM, GS and RU assisted with data extraction and verification. ABZ, AM and IK reviewed the methodology and contributed to the discussion of key findings. DH-E, GdlC, ACPA and EBT contributed insights that reflected their experience with health issues in developing countries. GM-K drafted the main text; NO-B and SP drafted the supplementary materials. ATL was responsible for conducting the metaregressions and produced all the figures and tables included in the manuscript. ATL, GM-K, NO-B and SP edited the text of the manuscript and the supplementary materials.
Funding The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Map disclaimer The inclusion of any map (including the depiction of any boundaries therein), or of any geographical or locational reference, does not imply the expression of any opinion whatsoever on the part of BMJ concerning the legal status of any country, territory, jurisdiction or area or of its authorities. Any such expression remains solely that of the relevant source and is not endorsed by BMJ. Maps are provided without any warranty of any kind, either express or implied.
Competing interests None declared.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.
Data availability online repository https://covid-ifr.github.io/
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.